Zastanawiałeś się kiedyś, jak usprawnić zarządzanie i monitorowanie maszyn wirtualnych w swoim środowisku Proxmox? QEMU Guest Agent to prawdziwy przełom, oferujący narzędzia, które znacząco ułatwiają interakcję z wirtualnymi systemami. Przyjrzyjmy się, jak to narzędzie może zmienić twoje podejście.
Dlaczego QEMU Guest Agent jest niezbędny?
Synchronizacja czasu: Utrzymanie spójnego czasu pomiędzy maszynami wirtualnymi a hostem może być trudne, ale QEMU Guest Agent automatyzuje to, zapewniając płynne działanie operacji zależnych od czasu.
Zarządzanie zasilaniem: Wyobraź sobie możliwość wyłączania lub restartowania maszyn wirtualnych bezpośrednio z panelu Proxmox — nie ma potrzeby logowania się do każdej VM. To nie tylko wygodne, ale także oszczędza czas.
Monitorowanie systemu: Uzyskaj szczegółowe informacje o systemach plików, aktywności sieciowej i innych parametrach operacyjnych bezpośrednio z hosta. Ten poziom monitorowania pozwala na terminową diagnostykę i regulacje.
Zarządzanie dyskami: Obsługa operacji na dyskach bez konieczności bezpośredniej interwencji na VM ułatwia tworzenie kopii zapasowych i przywracanie danych jak nigdy dotąd.
Konfiguracja QEMU Guest Agent na twoim serwerze Proxmox
Uruchomienie QEMU Guest Agent obejmuje kilka prostych kroków:
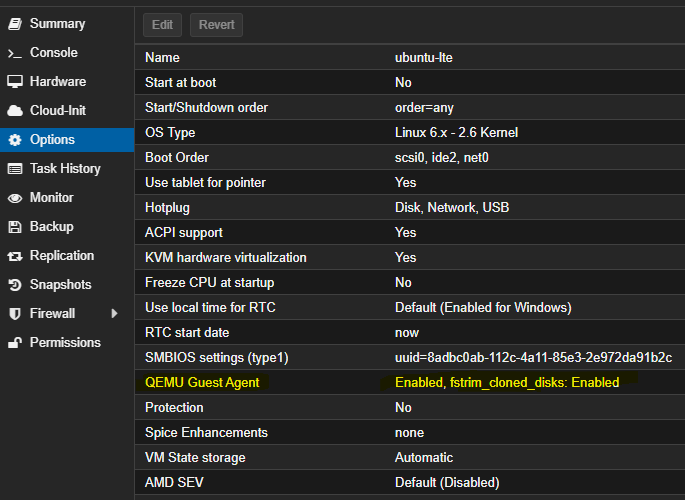
Aktywacja Agenta: Zaloguj się do panelu Proxmox, przejdź do sekcji 'Opcje’ wybranej maszyny wirtualnej i upewnij się, że opcja 'QEMU Guest Agent’ jest zaznaczona.
Następnie instalacja na maszynie wirtualnej Ubuntu:
Install QEMU Guest Agent
Shell
1
2
3
sudo apt-getinstall qemu-guest-agent
sudo systemctl start qemu-guest-agent
sudo systemctl enable qemu-guest-agent
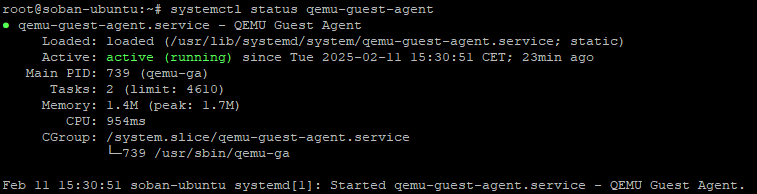
W celu sprawdzenia, czy odpowiednio działa qeumu-guest-agent możesz wykonać polecenie:
Check agent
Shell
1
systemctl status qemu-guest-agent
QEMU Guest Agent nie tylko ułatwia życie, automatyzując rutynowe zadania — również zwiększa bezpieczeństwo i efektywność twojego wirtualnego środowiska. Niezależnie od tego, czy zarządzasz pojedynczą maszyną wirtualną czy całym zbiorem, jest to nieocenione narzędzie w twoim arsenale.
Automatyzacja Zarządzania Przestrzenią Dyskową w Środowisku Linux
W dzisiejszym cyfrowym świecie, gdzie dane gromadzone są w coraz większych ilościach, zarządzanie przestrzenią dyskową staje się kluczowym elementem utrzymania efektywności operacyjnej systemów. W tym artykule przedstawię skrypt, który automatyzuje proces zarządzania przestrzenią na zdalnym dysku montowanym przez SSHFS, szczególnie przydatny dla administratorów systemów, którzy regularnie muszą radzić sobie z zapełniającymi się nośnikami danych.
Wymagania wstępne
Przed rozpoczęciem, upewnij się, że na twoim systemie zainstalowane jest SSHFS oraz wszystkie niezbędne pakiety umożliwiające jego prawidłową pracę. SSHFS pozwala na montowanie systemów plików zdalnych przez SSH, co jest kluczowe dla działania naszego skryptu. Aby zainstalować SSHFS oraz niezbędne narzędzia, w tym pakiet umożliwiający przekazywanie hasła (sshpass), użyj poniższego polecenia:
Instalacja SSHFS i sshpass
Shell
1
2
sudo apt-getupdate
sudo apt-getinstall sshfs fuse sshpass-y
Skrypt Bash do zarządzania przestrzenią dyskową
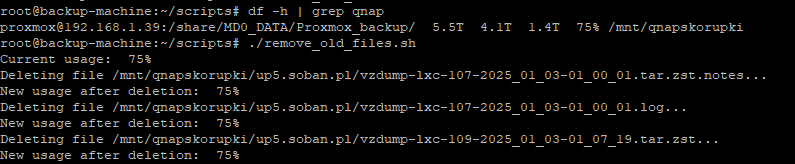
Nasz skrypt Bash skupia się na monitorowaniu i utrzymaniu określonego procentu wolnej przestrzeni dyskowej na zdalnym dysku, montowanym za pomocą SSHFS. Oto główne funkcje skryptu:
Definicja Celów:
TARGET_USAGE=70 – procent przestrzeni dyskowej, który chcemy utrzymać jako zajęty. Skrypt będzie działał na rzecz utrzymania przynajmniej 30% wolnego miejsca na dysku.
Punkt Montowania i Ścieżki:
MOUNT_POINT=”/mnt/qnapskorupki” – lokalny katalog, w którym montowany jest zdalny dysk. TARGET_DIRS=”$MOUNT_POINT/up*.soban.pl” – ścieżki katalogów, w których skrypt będzie szukał plików do usunięcia, jeśli zajdzie taka potrzeba.
Funkcja check_qnap: Ta funkcja sprawdza, czy dysk jest zamontowany i czy katalog montowania nie jest pusty. Jeśli są problemy, skrypt próbuje odmontować i ponownie zamontować dysk, używając sshfs z hasłem przekazanym przez sshpass.
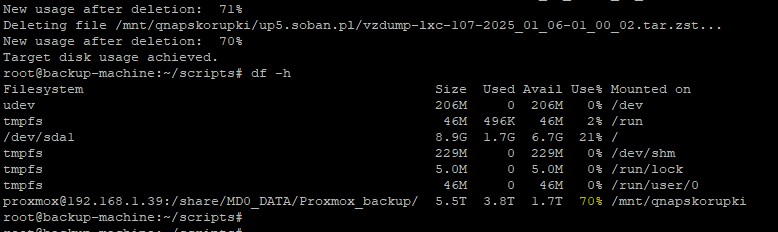
Usuwanie Plików: Skrypt monitoruje użycie dysku i, jeśli przekroczone jest TARGET_USAGE, znajduje i usuwa najstarsze pliki w określonych katalogach aż do osiągnięcia docelowego poziomu wolnej przestrzeni.
Pełny Skrypt Bash
Shell
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
#!/bin/bash
TARGET_USAGE=70
MOUNT_POINT="/mnt/qnapskorupki"
TARGET_DIRS="$MOUNT_POINT/up*.soban.pl"
# Function to check and mount SSHFS
functioncheck_qnap{
local remote_path="/share/MD0_DATA/backup_proxmox/"
local user_remote="remote_user"
local remote_host="192.168.1.XX"
local port=22
local password='XXXXXXXXXXXXXXXXXXXXXXX'
# Check if the mounting directory exists and is empty
if[!-d"$MOUNT_POINT"]||[-z"$(ls -A $MOUNT_POINT)"];then
echo"Problem: The directory $MOUNT_POINT is missing or empty. Attempting to remount..."
# Unmount if anything is currently mounted
ifmountpoint-q$MOUNT_POINT;then
echo"Unmounting $MOUNT_POINT..."
fusermount-u$MOUNT_POINT
sleep5
fi
# Remount
echo"Mounting SSHFS: $user_remote@$remote_host:$remote_path to $MOUNT_POINT..."
Należy zachować powyżej odpowiednią ścieżkę do skryptu.
Bezpieczeństwo i optymalizacja
Skrypt używa hasła wprost w linii komend, co może stanowić ryzyko bezpieczeństwa. W praktycznym zastosowaniu zaleca się użycie bardziej zaawansowanych metod autentykacji, na przykład kluczy SSH, które są bezpieczniejsze i nie wymagają jawnej obecności hasła w skrypcie. Jednak w przypadku QNAPa posłużyliśmy się hasłem pisząc ten skrypt.
Podsumowanie
Prezentowany skrypt jest przykładem, jak można automatyzować codzienne zadania administracyjne, takie jak zarządzanie przestrzenią dyskową, zwiększając tym samym efektywność i niezawodność operacji. Jego implementacja w realnych środowiskach IT może znacznie usprawnić procesy zarządzania danymi, zwłaszcza w sytuacjach, gdzie szybkie reagowanie na zmiany w użyciu dysku jest krytyczne.
Automatyczne wyłączanie laptopa przy niskim stanie baterii
Zachowanie długiej żywotności baterii i ochrona danych są kluczowe dla użytkowników laptopów. W tym artykule pokażemy, jak stworzyć prosty skrypt Bash, który automatycznie wyłączy Twój laptop, gdy poziom naładowania baterii spadnie poniżej 20%. Dodatkowo, dowiesz się, jak ustawić crontab, aby skrypt był uruchamiany co 10 minut, zapewniając ciągłe monitorowanie.
Tworzenie skryptu Bash
Skrypt Bash, który przygotowaliśmy, będzie sprawdzać aktualny poziom naładowania baterii i porównywać go z ustalonym minimalnym progiem. Jeśli poziom baterii spadnie poniżej tego progu, skrypt inicjuje wyłączenie systemu, co pomaga w ochronie danych i sprzętu.
Battery Check Script
Shell
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#!/bin/bash
# Define the minimum battery level before shutdown
Dzięki temu rozwiązaniu, możesz być spokojny o stan swojego laptopa nawet podczas intensywnego użytkowania. Automatyczne wyłączanie przy niskim stanie baterii nie tylko chroni sprzęt, ale także pomaga w utrzymaniu dłuższej żywotności baterii.
Poszerzanie przestrzeni dyskowej w wirtualnych maszynach Linux to kluczowy element zarządzania systemami serwerowymi. W tym artykule pokazujemy, jak efektywnie zwiększyć przestrzeń dyskową używając narzędzi LVM i fdisk, bazując na rzeczywistych danych z systemu.
Wstępne przygotowania
Przed przystąpieniem do zmian w partycjach i woluminach, ważne jest, aby sprawdzić aktualny stan dysków w systemie. Użyjemy polecenia lsblk, aby zidentyfikować dostępne dyski i partycje.
Shell
1
lsblk
Oto przykład wyniku polecenia lsblk na maszynie:
Shell
1
2
3
4
5
6
7
8
9
10
11
12
NAME MAJ:MIN RMSIZE RO TYPEMOUNTPOINT
loop07:0055.7M1loop/snap/core18/2829
sda8:0042G0disk
├─sda18:10512M0part/boot/efi
├─sda28:201G0part/boot
└─sda38:3040.5G0part
└─ubuntu--vg-ubuntu--lv253:0078.5G0lvm/
sdb8:160350G0disk
└─sdb18:17060G0part
└─ubuntu--vg-ubuntu--lv253:0078.5G0lvm/
sr011:011024M0rom
Tworzenie snapshotów
Zanim przystąpimy do zmian w konfiguracji dysków, zaleca się wykonanie snapshotu woluminów LVM, aby zapewnić możliwość przywrócenia danych w przypadku nieoczekiwanych problemów.
Następnie, przystępujemy do modyfikacji partycji, korzystając z fdisk. Usuwamy istniejącą partycję, a potem tworzymy nową, która wykorzysta całą dostępną przestrzeń na dysku sdb.
Shell
1
fdisk/dev/sdb
Zapis zmian
Po prawidłowym skonfigurowaniu partycji, korzystamy z komendy w w fdisk, aby zapisać zmiany i zaktualizować tabelę partycji.
Shell
1
Command(mforhelp):w
Wykonanie pvscan
Po modyfikacji partycji, wykonujemy polecenie pvscan, aby system mógł zaktualizować informacje o dostępnych fizycznych woluminach.
Shell
1
pvscan
Konfiguracja LVM
Po zapisaniu zmian w tabeli partycji, musimy zaktualizować konfigurację LVM, aby uwzględnić nową przestrzeń dyskową. Używamy polecenia lvextend z automatycznym rozszerzaniem systemu plików.
Shell
1
lvextend-l+100%FREE/dev/ubuntu-vg/ubuntu-lv-r
Podsumowanie
Rozszerzenie przestrzeni dyskowej na wirtualnej maszynie Linux poprawia wydajność i dostępność przestrzeni do przechowywania danych. Dzięki opisanym krokom, zarządzanie przestrzenią dyskową w systemach wykorzystujących LVM staje się prostsze i bardziej efektywne.
Podczas zarządzania klastrami Proxmox można napotkać różne trudności techniczne, takie jak niespójności w konfiguracji klastra lub problemy z przywracaniem kontenerów LXC. Znalezienie i rozwiązanie tych problemów jest kluczowe dla utrzymania stabilności i wydajności środowiska wirtualizacji. W tym artykule przedstawiam szczegółowy przewodnik, jak zdiagnozować i rozwiązać problem z nieosiągalnym węzłem oraz jak pomyślnie przywrócić kontener LXC.
Zanim przystąpisz do jakichkolwiek działań, upewnij się, że masz aktualny backup systemu.
Diagnostyka stanu klastra Proxmox
Shell
1
2
pvecm delnode up-page-02
Node/IP:up-page-02isnotaknown host of the cluster.
oraz:
Shell
1
2
pct restore107vzdump-lxc-107-2024_11_12-03_00_01.tar.zst--storage local
CT107already exists on node'up-page-02'
Aby zrozumieć stan klastra, wykonaj na węźle node-up-page-04 polecenie:
Shell
1
pvecm nodes
Oczekiwany output:
Shell
1
2
3
4
5
Membership information
----------------------
Nodeid Votes Name
11node-up-page-01
21node-up-page-04(local)
Następnie sprawdź szczegółowe informacje o klastrze za pomocą polecenia:
Shell
1
pvecm status
Oczekiwany output:
Shell
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
Cluster information
-------------------
Name:soban-proxmox
Config Version:4
Transport:knet
Secure auth:on
Quorum information
------------------
Date:Wed Nov1310:40:122024
Quorum provider:corosync_votequorum
Nodes:2
Node ID:0x00000002
Ring ID:1.e6
Quorate:Yes
Votequorum information
----------------------
Expected votes:2
Highest expected:2
Total votes:2
Quorum:2
Flags:Quorate
Membership information
----------------------
Nodeid Votes Name
0x000000011<masked IP>
0x000000021<masked IP>(local)
Usuwanie pliku konfiguracyjnego kontenera i czyszczenie danych
Odkryłem, że plik konfiguracyjny kontenera 107 wciąż istnieje na systemie plików klastra w ścieżce:
Proces przywracania zakończył się pomyślnie, a kontener był gotowy do użycia. Ten przypadek pokazuje, jak ważna jest dokładna diagnostyka i zarządzanie plikami konfiguracyjnymi w Proxmox podczas pracy z klastrami. Warto prowadzić regularne przeglądy konfiguracji, aby unikać niespójności i problemów operacyjnych w przyszłości.
Podczas codziennej pracy z bazami danych MySQL, mogą pojawić się specyficzne wyzwania, takie jak brakujące tabele lub błędy związane z nierozpoznaną bazą danych performance_schema. Te problemy mogą znacząco wpływać na wydajność i stabilność systemów bazodanowych, a ich diagnozowanie i rozwiązywanie bywa często skomplikowane i czasochłonne. Aby ułatwić to zadanie, stworzyłem ten przewodnik, który jest wynikiem moich doświadczeń oraz sprawdzonych praktyk. Zapewniam kompleksowe podejście do identyfikacji i naprawy problemów związanych z performance_schema. Jest to dosyć proste zaimportowanie schematu z nowo zbudowanej bazy danych.
Oczywiście przed całą operacją należy wykonać backup bazy najlepiej.
Początkowa diagnoza w MySQL
Zacznij od zidentyfikowania problemu w powłoce MySQL:
Upewnij się, że na twoich systemach zainstalowane są następujące pakiety, które są niezbędne do obsługi uwierzytelniania Kerberos oraz montowania systemów plików CIFS:
Instalacja pakietów
Shell
1
apt install krb5-user cifs-utils keyutils
Inicjalizacja biletu Kerberos
Zainicjuj bilet Kerberos za pomocą poniższego polecenia:
Inicjalizacja Kerberos
Shell
1
kinit twojanazwa@twojadomena.com
Aby zweryfikować ważność biletu i zobaczyć szczegóły, użyj:
Weryfikacja biletu
Shell
1
klist
Ręczne montowanie zasobów
Aby ręcznie zamontować zasób CIFS, użyj poniższego polecenia. Zamień twójserwer/twójzasób oraz /twójpunktmonowania na odpowiedni adres serwera i lokalny punkt montowania:
Te ustawienia są kluczowe, aby zapewnić bezpieczny i niezawodny dostęp do zasobów sieciowych przy użyciu Kerberosa w systemach Linux. Zawsze upewnij się, że twoje bilety Kerberos są ważne i odnawiaj je w miarę potrzeby. W przypadku problemów związanych z montowaniem lub uwierzytelnianiem, odwołaj się do dzienników systemowych lub skonsultuj się z administratorem systemu.
Serwery wirtualizacyjne bazujące na systemach z rodziny Debian, takie jak Proxmox, są często używane w środowiskach testowych, gdzie ciągła dostępność jest kluczowa. Czasami te serwery są instalowane na laptopach, które są wykorzystywane jako niskobudżetowe lub przenośne rozwiązania. Standardowe ustawienia zarządzania energią w laptopach mogą jednak prowadzić do niepożądanych zachowań, takich jak uśpienie lub hibernacja przy zamknięciu pokrywy. Poniżej opisuję, jak zmienić te ustawienia w systemie operacyjnym bazującym na Debianie, aby zapewnić nieprzerwaną pracę serwera.
Krok 1: Dostęp do pliku konfiguracyjnego
Otwórz terminal i wpisz poniższe polecenie, aby edytować plik /etc/systemd/logind.conf przy użyciu edytora tekstowego (np. nano):
Edycja logind
Shell
1
nano/etc/systemd/logind.conf
Krok 2: Modyfikacja ustawień logind
Znajdź linijkę zawierającą HandleLidSwitch i zmień jej wartość na ignore. Jeśli linia jest zakomentowana (poprzedzona znakiem #), usuń znak #. Możesz również dodać tę linię na końcu pliku, jeśli nie istnieje.
Shell
1
HandleLidSwitch=ignore
Krok 3: Zastosowanie i restart usługi
Po wprowadzeniu zmian i zapisaniu pliku, należy zrestartować usługę systemd-logind, aby zmiany weszły w życie. Użyj poniższego polecenia w terminalu:
Resetowanie systemd-logind
Shell
1
systemctl restart systemd-logind
Dzięki tym zmianom, zamknięcie pokrywy laptopa nie będzie już inicjować hibernacji ani uśpienia, co jest szczególnie ważne w przypadku korzystania z serwerów bazujących na Debianie, w tym Proxmox, jako rozwiązania serwerowe.
Zarządzanie pamięcią SWAP jest kluczowym elementem administrowania systemami operacyjnymi Linux, szczególnie w środowiskach wirtualizacji takich jak Proxmox. SWAP służy jako „pamięć wirtualna”, która może być używana, gdy fizyczna pamięć RAM systemu jest zapełniona. W tym artykule pokażemy, jak zwiększyć przestrzeń SWAP na serwerze Proxmox, korzystając z narzędzia lvresize do zwolnienia miejsca na dysku, które można następnie przeznaczyć na SWAP.
Przegląd problemu
Użytkownik chce zwiększyć przestrzeń SWAP z 8 GB do 16 GB, ale napotyka problem braku dostępnej przestrzeni w grupie woluminów LVM, która jest wymagana do zwiększenia SWAP.
Krok 1: Sprawdzenie dostępnej przestrzeni
Shell
1
vgs
To polecenie wyświetla grupy woluminów wraz z ich rozmiarami i dostępną przestrzenią.
Krok 2: Zmniejszenie wolumenu
Załóżmy, że istnieje wolumen root o rozmiarze 457.26 GB, który można zmniejszyć, aby uzyskać dodatkowe 8 GB na SWAP. Przed zmniejszeniem wolumenu konieczne jest zmniejszenie systemu plików na tym wolumenie.
Shell
1
resize2fs/dev/pve/root449.26G
Jednakże w przypadku systemu plików XFS, zmniejszenie musi nastąpić w trybie offline lub z live CD.
Krok 3: Użycie lvreduce
Shell
1
lvreduce-L-8G/dev/pve/root
To polecenie zmniejszy wolumen root o 8 GB, co potwierdza się komunikatem o zmianie rozmiaru wolumenu.
Krok 4: Deaktywacja SWAP
Shell
1
swapoff-a
Przed rozpoczęciem zmian w rozmiarze SWAP, należy najpierw wyłączyć SWAP za pomocą powyższego polecenia.
Krok 5: Rozszerzenie SWAP
Shell
1
2
3
lvresize-L+8G/dev/pve/swap
mkswap/dev/pve/swap
swapon/dev/pve/swap
Powyższe polecenia najpierw zwiększają przestrzeń SWAP, następnie formatują ją i aktywują ponownie.
Shell
1
swapon--show
Na koniec, weryfikujemy aktywne obszary SWAP używając polecenia powyżej, aby upewnić się, że wszystko zostało poprawnie skonfigurowane.
Proces ten pokazuje, jak można elastycznie zarządzać przestrzenią dyskową na serwerach Proxmox, dostosowując rozmiar SWAP w zależności od potrzeb. Użycie lvreduce wymaga ostrożności, gdyż każde działanie na partycjach i woluminach niesie ryzyko utraty danych, dlatego zawsze zalecane jest wykonanie kopii zapasowych przed przystąpieniem do zmian.
Pracując z MySQL, można napotkać różne błędy, które mogą zakłócić działanie systemu. Kod błędu 1114 jest jednym z nich i wskazuje na sytuację, gdy tabela, do której użytkownik próbuje zapisać dane, jest pełna. Ten problem jest szczególnie znaczący w systemie replikacji MySQL, gdzie jego rozwiązanie jest kluczowe dla zapewnienia ciągłości pracy.
Opis problemu
Błąd 1114 manifestuje się komunikatem: „Could not execute Write_rows event on table docs; The table 'docs’ is full”. Oznacza to, że nowe wiersze nie mogą zostać zapisane z powodu przekroczenia rozmiaru tabeli tymczasowej. Szczegółowy komunikat błędu może wyglądać tak:
Zaloguj się do MySQL:
Login to mysql
Shell
1
# mysql -u root -p
Zmień wartości zmiennej:
MySQL zmiana tmp_table_size i max_heap_table_size
MySQL
1
2
SET GLOBALtmp_table_size=268435456;-- Ustawienie na 256M
SET GLOBALmax_heap_table_size=268435456;-- Ustawienie na 256M
Po wprowadzeniu tych zmian, wszystkie nowe połączenia do serwera MySQL będą używać tych zaktualizowanych wartości. Możesz je sprawdzić, wykonując:
MySQL sprawdzanie tmp_table_size i max_heap_table_size
MySQL
1
2
SHOWGLOBALVARIABLESLIKE'tmp_table_size';
SHOWGLOBALVARIABLESLIKE'max_heap_table_size';
Albo
MySQL sprawdzanie tmp_table_size i max_heap_table_size
MySQL
1
SELECT@@tmp_table_size,@@max_heap_table_size;
Teraz replikacje można wznowić i powinna lepiej działać. Jednak należy pamiętaj, o modyfikacji konfiguracji, aby po restarcie mysqla zmienne te zostały poprawnie ustawione. Może być koniecznie tutaj wznowienie np replikacji (jeśli wcześniej została zatrzymana):
MySQL slave
MySQL
1
START SLAVE;
Jeśli problem został rozwiązany, na tym etapie sprawdzenie stanu replikacji:
Przed restartem usługi zalecane jest wykonanie SHUTDOWN; w kliencie MySQL. Należy pamiętać o wznowieniu replikacji.
Ważne uwagi
Zasoby systemowe: Upewnij się, że serwer dysponuje wystarczającą ilością pamięci RAM do obsługi zwiększonych wartości zmiennych.
Monitoring wydajności: Po dokonaniu zmian monitoruj wydajność, aby sprawdzić, czy problem został rozwiązany.
Trwałość konfiguracji: Zmiany w pliku konfiguracyjnym powinny być trwałe, aby uniknąć resetowania wartości po restarcie.
Dodatkowe kroki sprawdzające
Sprawdzenie dostępnej przestrzeni dyskowej: Możliwe, że problem wynika również z braku dostępnej przestrzeni na dysku. Można to sprawdzić za pomocą poniższej komendy:
Sprawdzenie dysku
Shell
1
# df -h
Podsumowanie
Rozwiązanie problemu związanego z kodem błędu 1114 w replikacji MySQL wymaga zrozumienia i dostosowania konfiguracji systemu. Opisane kroki pokazują, jak poprzez zwiększenie rozmiaru tabeli tymczasowej można zapobiec występowaniu tego błędu, co umożliwia sprawne działanie systemu replikacji.