Proxmox: Automatyczne aktualizacje VM (qm + vzdump) z testami sieci i auto-przywracaniem
W tym artykule opisuję prosty (ale bardzo skuteczny) skrypt automatyzujący aktualizacje maszyn wirtualnych na Proxmox VE. Skrypt potrafi:
- utworzyć backup maszyny (opcjonalnie),
- uruchomić VM, jeśli wcześniej była wyłączona,
- zrobić pełny upgrade systemu przez apt i wykonać reboot,
- zrobić testy sieciowe przed i po aktualizacji,
- w razie problemów automatycznie przywrócić VM z backupu (opcjonalnie),
- na końcu wyłączyć VM, jeśli wcześniej była wyłączona.
Skąd pobrać skrypt
Skrypt możesz pobrać bezpośrednio z mojej strony:
soban.pl/bash/upgrade_proxmox_qm.sh
Wymagane katalogi
Zanim uruchomisz automatyzację, utwórz dwa katalogi: jeden na skrypty i jeden na logi:
|
1 |
mkdir -p /root/automate_scripts /root/logs |
Instalacja skryptu
Pobierz skrypt do /root/automate_scripts/ i nadaj mu prawa wykonywania:
|
1 2 3 |
cd /root/automate_scripts curl -fsSL -o upgrade_proxmox_qm.sh "https://soban.pl/bash/upgrade_proxmox_qm.sh" chmod +x /root/automate_scripts/upgrade_proxmox_qm.sh |
Jak to działa (w skrócie)
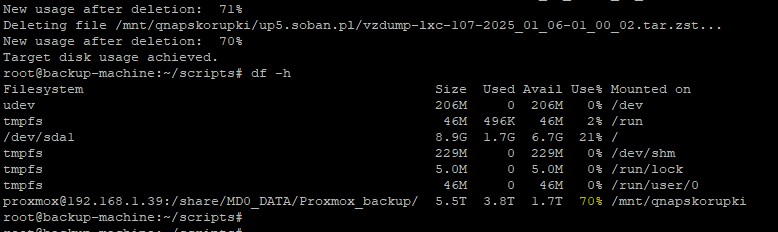
- Najpierw wykonywany jest backup (vzdump snapshot + zstd) – jeśli backup jest włączony.
- Jeśli VM była stopped, skrypt ją uruchamia i czeka WAIT_TIME sekund.
- Następnie wykonywane są testy sieciowe PRZED aktualizacją:
- Skrypt wykonuje apt update/upgrade/dist-upgrade/autoremove/clean i na końcu robi reboot VM.
- Po reboocie czeka ponownie (WAIT_TIME) i uruchamia te same testy PO aktualizacji.
- Jeśli testy nie przejdą i istnieje backup, skrypt wykonuje qmrestore automatycznie.
- Na końcu (opcjonalnie) wyłącza VM, jeśli wcześniej była wyłączona.
Uruchomienie (manualnie)
Skrypt przyjmuje dokładnie dwa argumenty:
VMID– ID maszyny wirtualnej na ProxmoxTIME_SEC– czas oczekiwania po starcie/reboocie (w sekundach)
|
1 |
/root/automate_scripts/upgrade_proxmox_qm.sh 901 500 |
Wskazówka: dobierz WAIT_TIME do realnego czasu bootowania VM oraz czasu trwania aktualizacji. Najczęściej sprawdza się 300 do 1000 sekund (zależnie od maszyny).
Pełny skrypt (do wklejenia / podglądu)
Poniżej wrzucam całość w jednym miejscu – dokładnie w takiej formie, w jakiej jest używana w tej automatyzacji:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 |
#!/bin/bash WAIT_TIME=$2 # wait time for VM start/restart (in seconds) DO_BACKUP="y" # 'y' - create backup, 'n' - skip backup DO_UPDATE="y" # 'y' - run system update, 'n' - skip update echo "---------------START---------------" date echo "-----------------------------------" # Argument check if [ "$#" -ne 2 ]; then echo "Usage: $0 <VMID> <TIME_SEC>" exit 1 fi VMID="$1" TARGET_HOSTNAME=$(/usr/sbin/qm list | grep -w "$VMID" | awk '{print $2}') VM_STATUS=$(/usr/sbin/qm status "$VMID" | awk '{print $2}') HOST_MACHINE=$(hostname) WAS_STOPPED=0 if [ "$VM_STATUS" = "stopped" ]; then WAS_STOPPED=1 else WAS_STOPPED=0 fi # Create backup if DO_BACKUP is set to 'y' backup_result="Backup not attempted" if [ "$DO_BACKUP" = "y" ]; then echo "Creating backup for VM $VMID..." BACKUP_OUTPUT=$(/usr/bin/vzdump "$VMID" --storage local --mode snapshot --compress zstd) BACKUP_FILE=$(echo "$BACKUP_OUTPUT" | grep -oP 'vzdump-qemu-[^\s]+' | tr -d "'") if [ -z "$BACKUP_FILE" ]; then echo "Backup failed: No backup file created." backup_result="Backup created: NOK" exit 1 else echo "Backup created successfully: $BACKUP_FILE" backup_result="Backup created: OK" fi else echo "Backup not attempted (backup is disabled)." fi # Start VM if it was originally stopped if [ "$WAS_STOPPED" -eq 1 ]; then echo "Starting VM $VMID for update..." /usr/sbin/qm start "$VMID" echo "Waiting $WAIT_TIME seconds for VM to start..." sleep "$WAIT_TIME" fi # Test functions perform_ping_test() { source="$1" target="$2" if ssh root@"$source" "ping -c 3 -W 2 $target" >/dev/null 2>&1; then echo "Ping from $source to $target: OK" return 0 else echo "Ping from $source to $target: NOK" return 1 fi } test_curl() { source="$1" target="$2" if ssh root@"$source" "curl -s --head --connect-timeout 5 $target" >/dev/null 2>&1; then echo "Curl from $source to $target: OK" return 0 else echo "Curl from $source to $target: NOK" return 1 fi } perform_local_ping_test() { source="$1" target="$2" if ping -c 3 -W 2 "$target" >/dev/null 2>&1; then echo "Ping from $source to $target: OK" return 0 else echo "Ping from $source to $target: NOK" return 1 fi } DEFAULT_GW=$(/sbin/ip route | grep default | awk '{print $3}') perform_tests() { status=0 perform_local_ping_test "$HOST_MACHINE" "$TARGET_HOSTNAME" || status=1 perform_ping_test "$TARGET_HOSTNAME" "8.8.8.8" || status=1 perform_ping_test "$TARGET_HOSTNAME" "$DEFAULT_GW" || status=1 test_curl "$TARGET_HOSTNAME" "http://google.com" || status=1 return ${status:-0} } # General tests before update echo "--- General tests BEFORE update ---" if perform_tests; then echo "All network tests before update: OK" echo "$backup_result" if [ "$backup_result" == "Backup created: OK" ] || [ "$backup_result" == "Backup not attempted" ]; then echo "BEFORE status: OK" else echo "BEFORE status: NOK" fi else echo "Some network tests before update: NOK" echo "$backup_result" echo "BEFORE status: NOK" [ "$WAS_STOPPED" -eq 1 ] && /usr/sbin/qm shutdown "$VMID" exit 1 fi echo "-----------------------------------" # System update and reboot update_result="Upgrade system: NOK" if [ "$DO_UPDATE" = "y" ]; then echo "--- Updating VM $VMID ---" if ssh root@"$TARGET_HOSTNAME" "/usr/bin/apt update && \ /usr/bin/apt upgrade -y && \ /usr/bin/apt dist-upgrade -y && \ /usr/bin/apt autoremove -y && \ /usr/bin/apt autoclean && \ /usr/bin/apt clean && \ /usr/bin/apt --purge autoremove && \ /sbin/reboot"; then echo "---END Updating VM $VMID ---" echo "Upgrade system: OK" update_result="Upgrade system: OK" else echo "Upgrade system: NOK" update_result="Upgrade system: NOK" [ "$WAS_STOPPED" -eq 1 ] && /usr/sbin/qm shutdown "$VMID" echo "Update failed. Exiting." exit 1 fi fi # Wait for VM reboot if update was performed if [ "$DO_UPDATE" = "y" ]; then echo "Waiting $WAIT_TIME seconds for VM to reboot..." sleep "$WAIT_TIME" fi # Tests after reboot if update was performed if [ "$DO_UPDATE" = "y" ]; then echo "--- Network tests AFTER update ---" if perform_tests; then echo "All network tests after update: OK" echo "$update_result" echo "AFTER status: OK" else echo "Some network tests after update: NOK" echo "$update_result" echo "Attempting to restore from backup..." if [ "$DO_BACKUP" = "y" ]; then /usr/sbin/qm stop "$VMID" /usr/sbin/qmrestore "/var/lib/vz/dump/$BACKUP_FILE" "$VMID" --force if [ "$WAS_STOPPED" -eq 1 ]; then /usr/sbin/qm shutdown "$VMID" fi echo "Restore attempt finished. Please check VM status." echo "AFTER status: NOK" else echo "No backup available for restoration. The VM might not function properly after failed update." echo "AFTER status: NOK" fi fi echo "-----------------------------------" fi # Shut down VM if it was originally stopped if [ "$WAS_STOPPED" -eq 1 ]; then echo "Shutting down VM $VMID (originally stopped)." /usr/sbin/qm shutdown "$VMID" fi echo "---------------END---------------" date echo "-----------------------------------" |
Cron (harmonogram tygodniowy + osobne logi per VM)
Poniżej masz przykład crontaba, który uruchamia aktualizacje raz w tygodniu (inna VM każdego dnia roboczego) i zapisuje logi do osobnych plików w /root/logs/.
Edytuj crona roota:
|
1 |
crontab -e |
Wklej reguły (komentarze są po angielsku):
|
1 2 3 4 |
15 0 * * 1 /root/automate_scripts/upgrade_proxmox_qm.sh 901 500 > /root/logs/kali.log 2>&1 # Monday: upgrade Kali Linux (VMID 901) 15 0 * * 2 /root/automate_scripts/upgrade_proxmox_qm.sh 903 500 > /root/logs/proxmox-test-01.log 2>&1 # Tuesday: upgrade proxmox-test-01 (VMID 903) 15 0 * * 3 /root/automate_scripts/upgrade_proxmox_qm.sh 904 500 > /root/logs/ubuntu-lte.log 2>&1 # Wednesday: upgrade ubuntu-lte (VMID 904) 15 0 * * 4 /root/automate_scripts/upgrade_proxmox_qm.sh 905 1000 > /root/logs/backup-machine.log 2>&1 # Thursday: upgrade backup-machine (VMID 905) |
Szybkie checklisty / troubleshooting
- Upewnij się, że root z hosta Proxmox może łączyć się po SSH do VM po hostname (skrypt używa
ssh root@<vm-hostname>). - Sprawdź czy DNS (albo
/etc/hosts) poprawnie rozwiązuje hostname VM na hoście Proxmox. - Jeśli apt potrafi pytać o potwierdzenia, zadbaj o tryb non-interactive albo „trzymaj” pakiety, które robią problemy podczas upgrade.
To wszystko. Umieść skrypt w /root/automate_scripts/, wyślij logi do /root/logs/, a cotygodniowa konserwacja maszyny wirtualnej stanie się praktycznie niezauważalna.